
Artificial Intelligence for History Data
AI is bringing changes to many things, and the study of history is one of them. Running Reality is taking a balanced approach to AI as a tool to help us realize our vision of a digital time machine. Protecting your trust in our platform is critical for us. Therefore, we are using AI for select tasks where we can monitor the data quality, bring you more data than ever, and visualize history in more immersive ways.
Overview
AI tools are becoming ubiquitous in history education and research. Just a few years ago, AI for history meant niche research tools for Natural Language Processing (NLP) or image analysis using a traditional Convolutional Neural Network (CNN) model. The new Generative Transformer models, now known collectively as "GenAI" or Generative AI, changed all that.
The American Historical Association has issued a very thoughtful whitepaper on using AI in education and on the future of integrating AI into the discipline of history. Some key conclusions are:
- "Historical thinking remains essential in an age of AI."
- "Many disciplines and professions are changing; the historical discipline will too."
- "Banning generative AI is not a long-term solution; cultivating AI literacy is."
- "History educators must develop concrete and transparent policies for AI usage and communicate these to students."
- "Generative AI cannot replace historical methodology."
- "There are no shortcuts to expertise."
The internet has now been flooded with what people are calling "AI slop" including images, articles, and videos aimed at history enthusiasts. Want a video of walking down a street in ancient Egypt? Want to insert yourself into a historical scene with Julius Caesar? It is just a click away. Over the years, documentaries and video games and pop movies have been recreating history for some time, and with a wide variation in quality and historical accuracy. Just because the movie "300" had only a loose connection to the real history doesn't mean that all movies are inherently inaccurate.
We are working to build an immersive time machine experience and keep that free for students, educators, and history enthusiasts. Tools build what we choose to build. So, what does it look like to take these new tools to make next-generation historical experiences that are also carefully accurate? Here are some of our basic assumptions:
- AI is here to stay and will become a better tool over time.
- People's expectations for an immersive history experience will rise.
- Good history tools can be built to meet those expectations.
| Data | Task | AI Tools | Output |
|---|---|---|---|
| Historical Text | Generative Transformer models to convert narrative text into structured data. | LLMs: OpenAI GPT, Anthropic Claude, Google Gemini | Factoids |
| Historical Maps | Semantic Segmentation models to identify polygonal map features. | Facebook SAM2 | 2D Features, Factoids |
| Historical Photos | Photogrammetry models to create 3D models of buildings and people. | Google Gemini (Nano Banana), Meshy.ai | 3D Models |
This article lays out our philosophy, how we are implementing it, and how we are balancing ethical, technological, pedagogical, and public-accountability concerns.
Documenting "Why"
Have you seen fully immersive 3D reconstructions of ancient cities on the internet? There are some really amazing and well researched videos on YouTube. However, social media is also now being flooded with easy to make Generative AI videos purporting to be ancient scenes. These Generative AI videos are an extraordinary technical achievement and improve in their accuracy with each passing month. However, even if it is fairly accurate, there is no transparency, citation, or auditability. How can we keep up with Generative AI and hold to our principles of accuracy?
 A fanciful view of the waterfront of Alexandria, Virginia, USA in 1780 as visualized by OpenAI's ChatGPT.
A fanciful view of the waterfront of Alexandria, Virginia, USA in 1780 as visualized by OpenAI's ChatGPT.
A central tenant of Running Reality is that it does not just present historical information but it tells you why it showed what it did. If data can directly from a source, there will be an underlying factoid with a citation. If the visualization has had inference, then that should also be clear. We want people to feel like they have an immersive, dynamic time machine at their finger tips, but also one they can trust and see the "proof of work." What does using advanced technology in a responsible, ethical, and transparent way look like today? Documenting "why" is at the root of it.
Transformation versus Inference
Running Reality has always been an inference engine, since the first version of the engine in 1997. The history engine takes the factoids and is authorized to make inferences about movements, borders, populations, etc in between those factoids. The distinction between factoids and inference has always been clear and is fundamental to the idea of the factoid. Many design choices about factoids have been specifically made to minimize any inference inherent to a factoid. AI is a more advanced form of inference and will be used in a clear way to make inferences better and richer.
This distinction between factoids and inference is central. For factoids, AI (and humans) may transformed data from citable sources into the factoid format, but it must be verifiable. For inference between factoids, the engine may use algorithms or AI. If either a factoid or inference is historically inaccurate, either because of new discoveries or better research, then the solution is more, better factoids to guide the engine.
Historical Maps
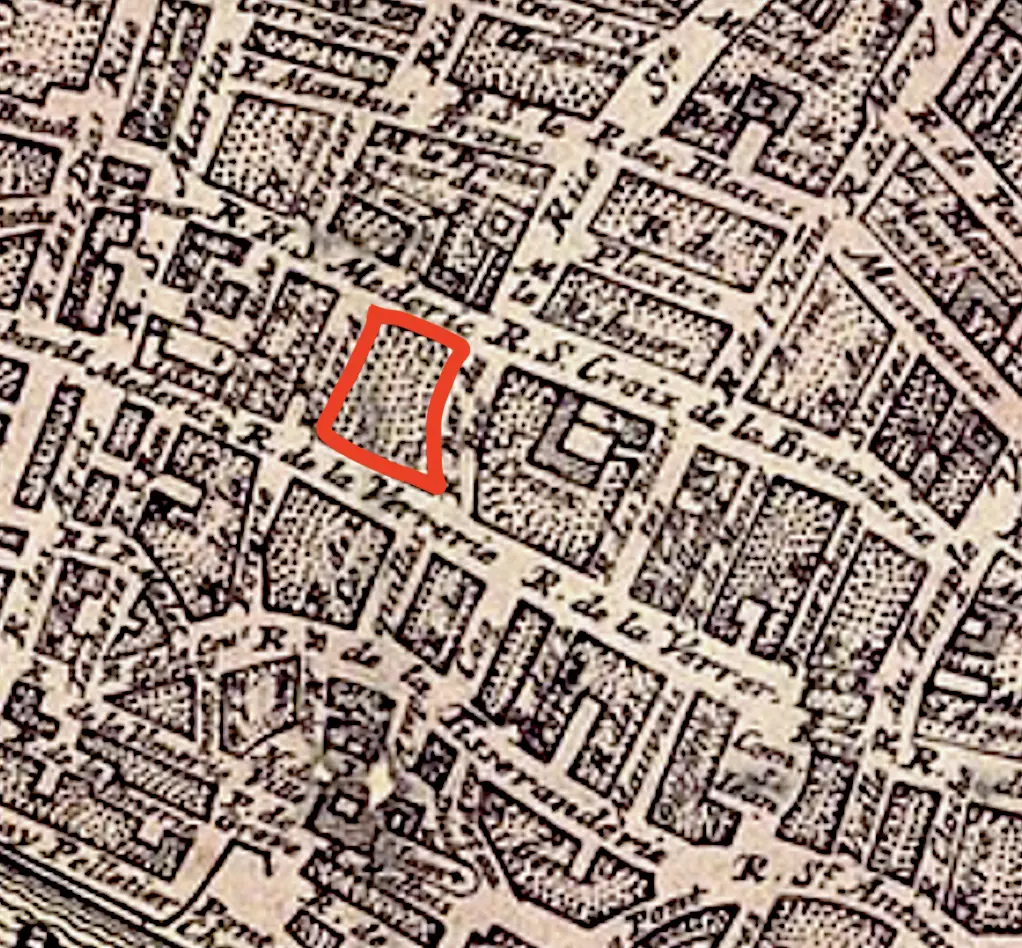
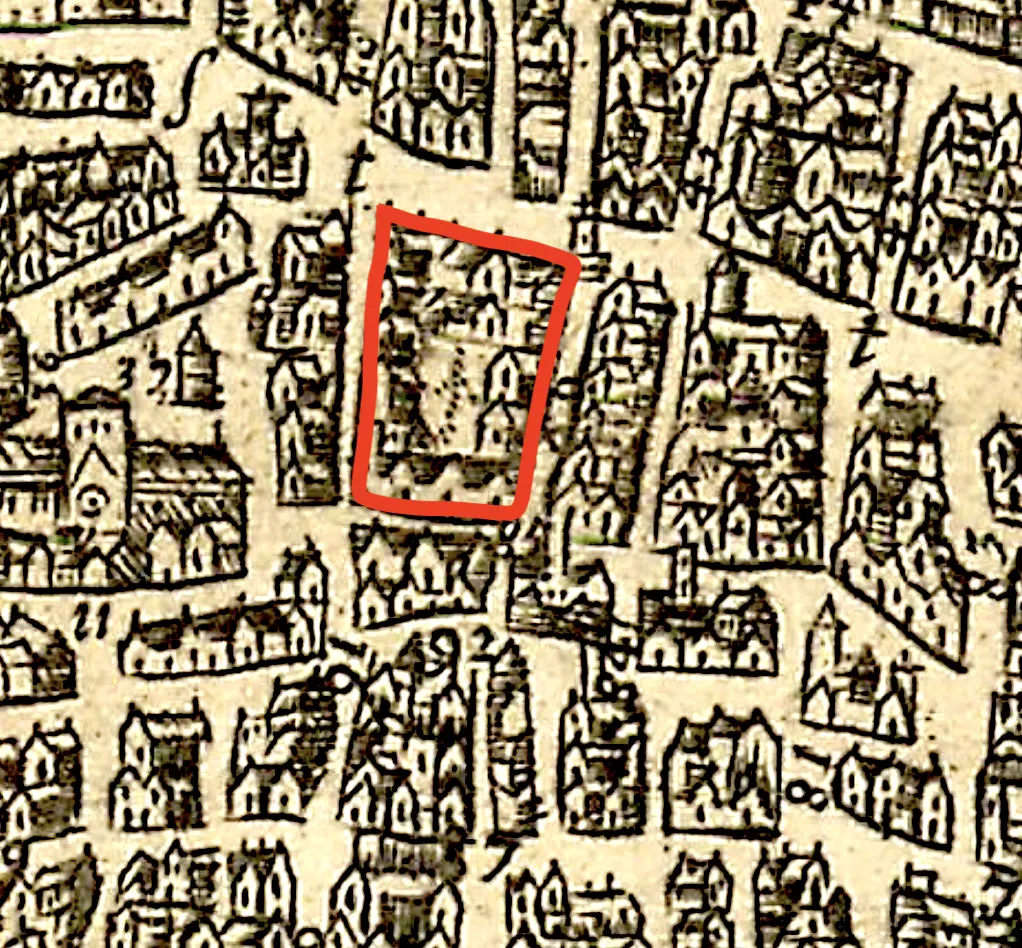
Historical maps are notoriously difficult for machines to interpret, whether AI or not, and often even for people to interpret. Georectification or georeferencing of historical maps is probably the most tedious and time consuming step before any useful data can be identified, and it is entirely manual. Key features on the historical map must be given Ground Control Points in modern coordinates, then the map is "warped" so that all other features are properly positioned. Non-standard symbols, poor surveying instruments, bias due to political factors, survey gaps, and other factors also contribute to the challenge.
{kind=link}
{kind=link}
Where machine learning can help is at a more fundamental level. Machine learning models for image processing and analysis can identify polygons, lines, and text on historical maps. These models use traditional neral networks to identify contiguous pixel areas plus more advanced capabilities to better understand the context of intersecting and overlapping features plus visual imperfections. Features in maps that are clear and distinct polygons can be identified and imported using the "Identify Features" tool to attempt to pick out a polygon from the map.
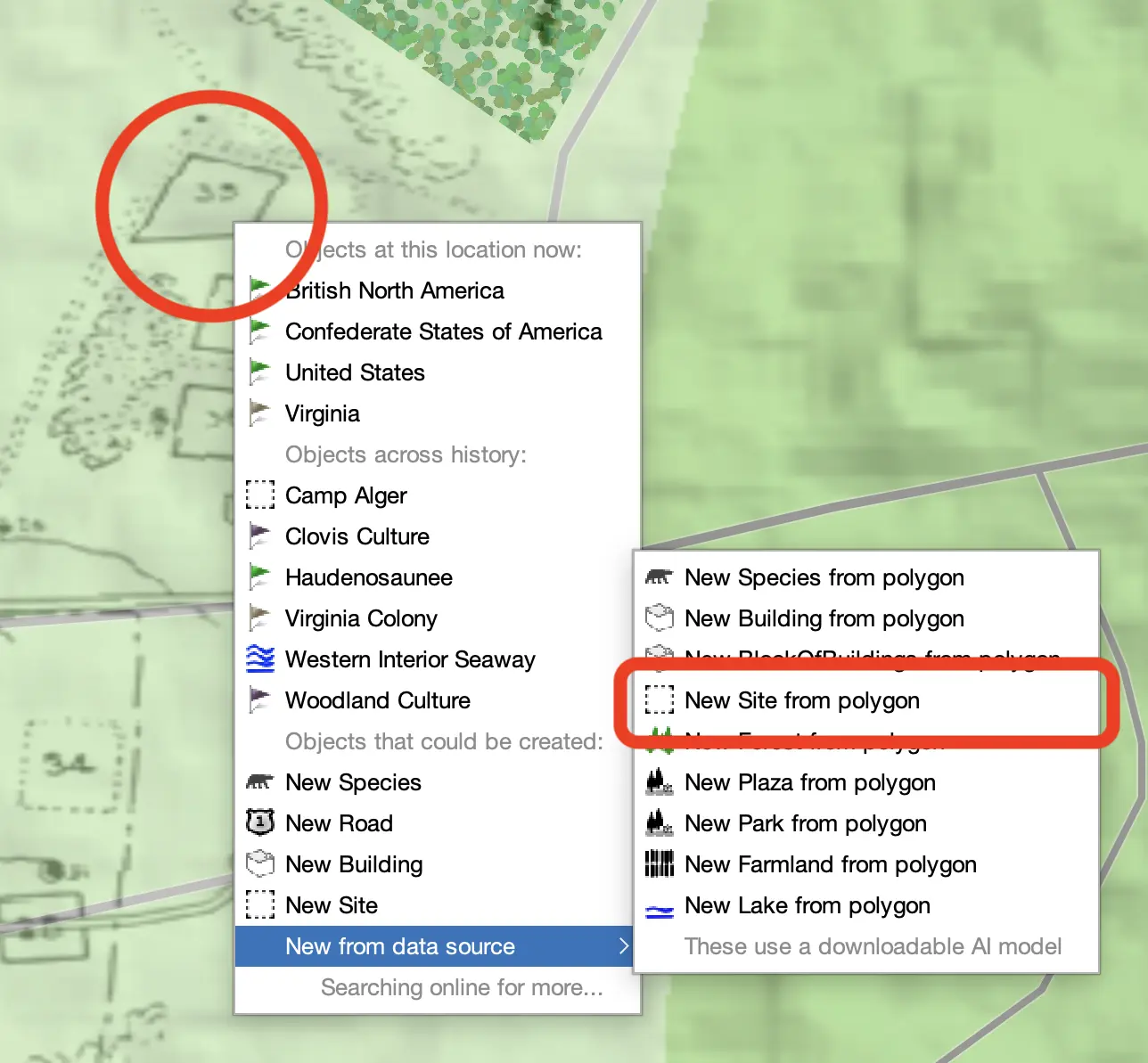
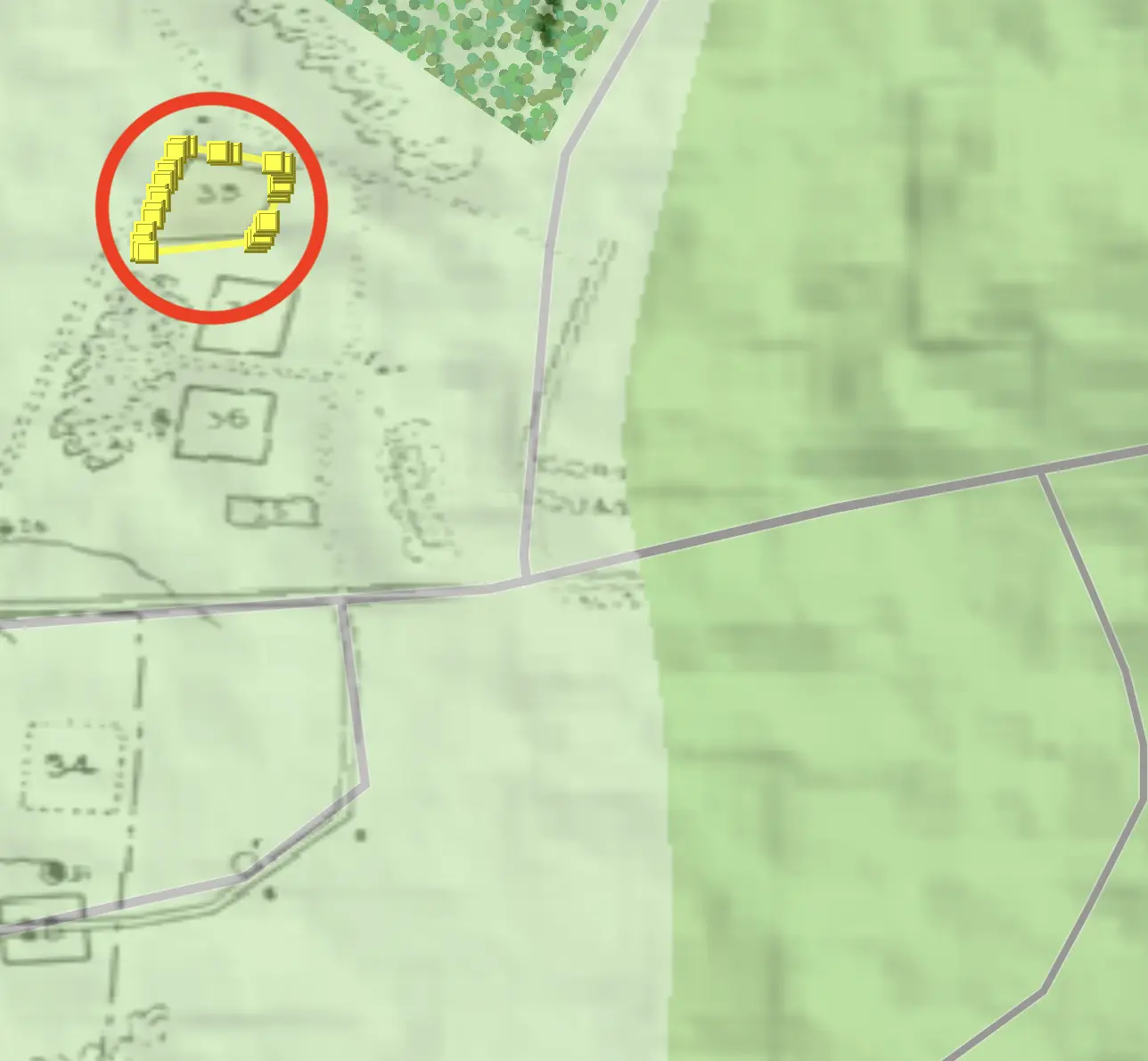
The primary model we rely on is a separately downloadable (separately licensed) model known as the Segment Anything Model 2 (SAM2). This model uses a concept called "semantic segmentation," which combines traditional image processing with machine learning models to identify patterns with new models that also understand the context and meaning of the patterns they are assessing to better group pixels into semantically-coherent shapes. This has proven to be more effective with historical maps.
There are other exciting projects working to use machine learning to extract data from historical maps. The DesCartes project is working on techniques to extract roads from the British Ordinance Survey maps, tuning their model to the specific line conventions of those maps to distinguish fences and paths from roads. Text-based search and semantic search is being developed by multiple teams, including the David Rumsey map collection. They are scanning the maps for place name labels then comparing those to a historical gazetteer. This enabled both a basic search for maps of a place by its modern or historical spellings but also the possibility of accelerating georeferencing the map by aligning the historical label to a known, precise modern coordinate. Running Reality does not collect historical maps, but benefits when the data inherent in such maps is easier to access.
Historical Photos
Running Reality believes it is critical to make available high-quality 3D visualizations that balance the need for an immersive historical experience with the need for research rigor. We will strive to adhere to the London Principles while carefully using Generative AI. We will make sure to extend the citation and sourcing approach we have used for other data into the 3D world. We will be respectful of people's trust.
Running Reality is taking multiple approaches to representing uncertainty in its visualizations. Our migration to a more immersive 3D model is underway and we are doing it in steps to get feedback on each step.
We are being careful in implementing this system to factor in the following:
- The same history engine inference system must be able to interpolate and extrapolate data over time.
- The source of the data must remain transparent and auditable, even if the structure contains a mixture of provenance.
- Uncertain and composite data, where height, material, architectural style, and condition may be separately cited factoids.
- There is linked data, such as interior spaces being linkable to people or businesses.
- Generative AI is making detailed 3D models more available, but with an extra burden of citation.
Using photogrammetry with historical drawings, illustrations, and photographs offers an tremendous opportunity. With photogrammetry, we can quickly build 3D models that are at the same level of historical accuracy as the source material. This can strongly enhance the sense of immersion in history while introducing a defined, transparent, and traceable level of inference.
As an example, here is our basic 2D and basic 3D augmented reality view of the Carlyle Warehouse on the Alexandria, Virginia, waterfront in about 1780. The building's dimensions are known from excavation, as is the basic wooden material. The site of the building is now roughly located under the present-date Indigo Hotel. However, rendering the warehouse as a plain block of wood with those dimensions is not very compelling.
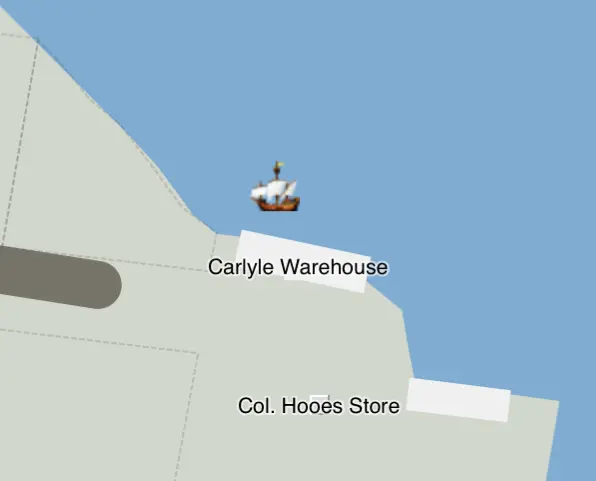 Our basic 2D map of the waterfront of Alexandria, VA.
Our basic 2D map of the waterfront of Alexandria, VA.
 The basic map data rendering in 3D augmented reality while standing in Alexandria, VA.
The basic map data rendering in 3D augmented reality while standing in Alexandria, VA.
There is an artist's rendering of the Alexandria waterfront representing this era that hangs in the Alexandria Archaeological Museum two blocks away from the warehouse site. The artists has attempted to properly represent Alexandria at this time, and though there is some artistic interpretation, it is considered sufficiently accurate to hang in the museum to give people an immersive understanding of Alexandria. It is understood by visitors not to be data, but art serving a purpose.
We used photogrammetry to create a 3D model that follows from the artists impression. This is similar to how such art was used to train the generative AI model used to create the fanciful scene at the top of this article. When asked to perform a more narrow task of creating this single warehouse and to use a specifically citable reference work, we have constrained the inferences made. Further, the 3D model can now be shown in Running Reality alongside other citable data points. When clicking the warehouse, the dates, locations, dimensions, and other data have their citations, and the 3D model has a citation to the artists work.
 An artist's painting of the Alexandria waterfront that hangs in the Alexandria Archaeological Museum.
An artist's painting of the Alexandria waterfront that hangs in the Alexandria Archaeological Museum.
 The artist's impression of the warehouse was used to guide a generative AI tool to create a 3D model.
The artist's impression of the warehouse was used to guide a generative AI tool to create a 3D model.
 The updated 3D model shown in 3D augmented reality gives a better sense of what the waterfront was like.
The updated 3D model shown in 3D augmented reality gives a better sense of what the waterfront was like.
Advanced photogrammetry today combines techniques such as "gaussian splatting" and machine learning to reconstruct depth of field from a single or multiple photos. Additional generative AI may be used to reconstruct or infer hidden elements based on other related photographs.
The London Charter for the Computer-based Visualisation of Cultural Heritage is the leading set of principles for digital history projects to ensure they follow sufficient methodological rigor. Running Reality attempts to follow these principles.
Historical Text
Running Reality is taking an experimental and balanced approach to using Generative AI on historical texts and texts about history. The class of machine learning models known as Generative Transformers has advanced rapidly with the use of "context" or "attention" buffers to augment the traditional Convolutional Neural Networks. They have now moved far beyond knowledge encoding (vector embedding) and classification. They can now transform narrative historical text into structured text with high reliability. Just as a human would take a cite-able source and transform it into factoids, so can an AI.
We run periodic tests on both frontier models and open source models to see how well they can transform narrative historical text into structured data. Recent tests show that frontier models have progressed to the point where they are highly accurate on extracting many kinds of data, such as names, dates, relationships, and events. They are still unable to handle location reliably. They can be made to generate proper citation, but it takes additional wrapper code to ensure the LLM is given sources to use and then to perform post-transformation checks on the citations and evidence to validate it. These cross-checks are necessary for humans as well. Interestingly, the open source models, which are not as capable as the frontier models, are also surprisingly accurate. They are currently (mid-2026) accurate on 90-95% of generated factoids. The primary difference with frontier models is that the open source models miss data points that could have been identified by a human or frontier model.
Hence, factoids generated by or with assistance from LLMs are allowed, with the following conditions:
- A human submits the factoids. A human is always accountable for the correctness of the data and the citation.
- A human reviews the factoids. The human review of a factoid submission is a safety net and the submitter is the one to attest to the factoid's accuracy.
- The AI was used as a data transformer. If an AI transforms a Wikipedia page, then the resulting factoids have a citation and can be verified against the page.
All factoid data must be verifiable. Today, we do not rely on an LLM to generate factoids inferred from its training data, only use it to transform a specific source. This is because the specific item(s) from an LLM’s training data that resulted in the specific output factoid can’t be specifically cited or audited. If this changes with future iterations of LLMs, this policy may evolve. LLMs have memorized all of Wikipedia and thousands of history books, so their outputs may indeed be correct and may indeed be based on reliable sources. However, these factoids do not have a specific citation that can be used for verification.
| Transformation | Inference |
|---|---|
Generate factoids from the following article about the Battle of XYZ, with specific factoids for all people and military units mentioned in the article. [article text attached] |
Who was at the Battle of XYZ? Create specific factoids for all people and military units who were there. |
Humans make mistakes with factoids and so will AI, but the goal is to have processes that keep such mistakes to a minimum and to have an open, auditable factoid trail so corrections can be made later. If either a human or AI-generated factoid is historically inaccurate, either because of new discoveries or better research, then the solution is more, better factoids to guide the engine.
Others are doing interesting work with text-based machine-learning models. There are teams looking at whether an LLM's ability to predict the next-most-likely word in a sentence can help fill in missing letters or words from ancient inscriptions on stones or tablets that are incomplete, damaged, broken, or worn.
Conclusion
The rise of generative AI historical imagery, video, and 3D models is presenting researchers, history students, and enthusiasts with a challenge. We believe that using the principles of the London Charter will provide confidence in Running Reality and the historical visualizations it creates. We will integrate different kinds of AI carefully, including GenAI Generative Transformer models, Sematic Segmentation models, and Photogrammetry models. This fits well with out existing data-driven inference engine already tested and trusted for accuracy and transparency. There is an opportunity opening for advanced new tools for historical maps, historical photos, and historical texts.